
Any organization working within the cloud has to administer multiple, complex challenges to security and reliability, while keeping a good rein on costs. Your brand’s fame depends upon managing these challenges with aplomb, ensuring that you just handle threats and failures quickly, transparently, and efficiently. Increasingly, organizations are selecting an open-source service mesh to assist avoid downtime—while driving potentially game-changing business advantages, including drastic reductions in cloud spend.
Eliminate Downtime
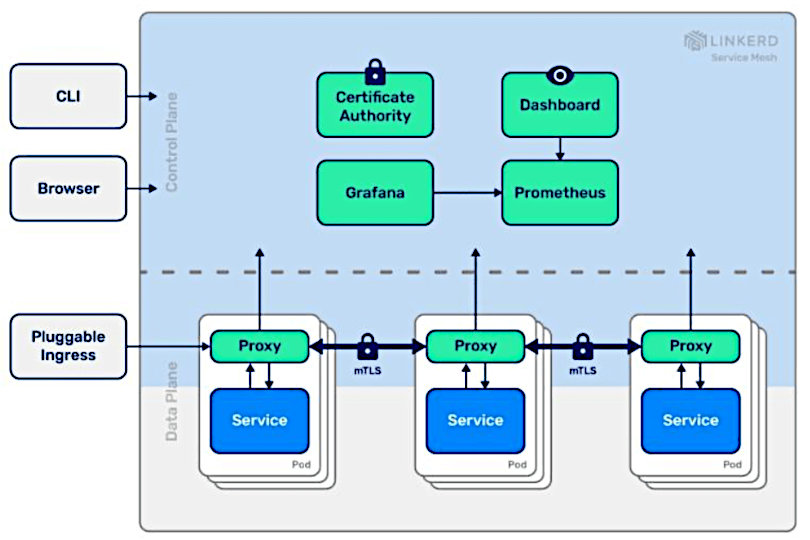
The shift to cloud-native technologies has fundamentally modified application development from a world where applications run on hardware and networks completely controlled by the developing organization to a world where that control is traded for lower costs and speed in the event cycle. In turn, this tradeoff requires the organization to embrace latest cloud-native patterns, like microservices, Kubernetes, and using a service mesh, in order that the appliance still has needed security and resilience.
These latest patterns allow shifting the safety boundary entirely from physical data-center security to application security, including ensuring that each one data is encrypted each at rest and in transit. The service mesh plays a critical role on this shift, by adding security, reliability, and observability to the appliance in a way that minimizes developer involvement.
For instance, Linkerd, the primary open source service mesh to realize the “graduated” status within the Cloud Native Computing Foundation, uses sophisticated techniques akin to mutual TLS to safeguard each confidentiality (encryption) and authenticity (identity validation) of either side of the connection for all traffic inside an application. Linkerd does this completely transparently, without the appliance needing to vary.
Moreover, the mesh’s observability features can allow the operations staff to see problems on a Friday night before they develop into an emergency. And its reliability features can prevent needing to call in a developer team to work the weekend—as an alternative, the operations staff can simply configure the mesh for automatic retries, preserving the user experience and leaving the more intense problem attempting to find Monday.
Realize Cost Savings
Service meshes offer direct and secondary cost savings. The mesh can reduce direct cloud costs by allowing organizations to eliminate load balancers within the cloud and reduce some network traffic. In some cases, organizations have been in a position to eliminate lots of of paid IP addresses for microservices.
In cases where the organization is running clusters spanning multiple availability zones, some service meshes like Linkerd may even further reduce costs by fastidiously routing traffic (or handling outages) in order that traffic stays inside a zone, which costs lower than traffic between zones. This could bring dramatic reductions in cloud network spend (thousands and thousands of dollars a 12 months) while still retaining the failure-resistant properties of multi-zone deployments, as within the case of Entain Australia, which 10x’d throughput and saved hundreds of dollars a day by deploying Linkerd.
Service meshes also offer secondary cost savings resulting from the increased efficiency of developers. By delivering critical platform features like mutual TLS, latency-aware load balancing, retries, success rate instrumentation, transparent traffic shifting, and more, service mesh frees developers of those tasks, allowing them to give attention to the business logic that drives the organization. These savings are significant. Critical platform maintenance could be incredibly difficult to get right in a big distributed system, placing undue pressure on application developers.
Protect your Status
Operational continuity—and the supply of online services—leaves organizations with no slack. Users have come to expect fast access at any time of the day. In a distributed system, IT outages that start as partial failures in a single area can quickly escalate into major operational disruptions that impact the shopper experience. Issues, errors, or delays reflect on the organization or the brand.
A service mesh delivers a complicated set of distributed system reliability features that may help prevent escalation in the primary place, including request-level load balancing, timeouts, retries, rate limiting, circuit breaking, and traffic shifting. Some service meshes even provide powerful features like latency-based load balancing and retry budgets to tamp down on partial failures before they escalate.
Service Mesh for All?
What type of organizations can profit from service mesh? Use cases suggest that just about every organization creating cloud apps in Kubernetes may gain advantage—including small start-ups. Not only does the service mesh provide operational simplicity, but it might also enhance progress for application developers at every stage of a company’s growth.
Some open-source service meshes have a fame for complexity. Others were designed to be operationally easy yet powerful, allowing organizations to see immediate advantages. Selecting the proper mesh, one that gives critical features “out of the box,” frees the engineering team to give attention to fundamental applications that power the business, providing a competitive advantage.
Compare Notes
Uses cases for service mesh come from industry leaders that include Microsoft, Plaid, and Adidas. These firms, all with global users, have realized the business advantages of making scalable systems with resilient infrastructure that features automatic retries, circuit breakers to isolate faults, and seamless restore functionality. Service mesh helps them detect where failures are happening with advanced observability and provides Zero Trust security system-wide.
- Microsoft’s Xbox, a gaming system, uses service mesh to reinforce consistency across the platform, allowing multiplayer games within the Xbox Network.
- Plaid, a world financial services provider, uses service mesh to speed up their production and implement changes in as little as half-hour, an unheard-of speed within the financial world.
- Adidas, a world athletic brand, uses service mesh for system redundancy, security, and automatic prioritization of network traffic.
Measure The Impact
The business impacts of using service mesh could be seen in a company’s overall uptime (increased), overall spending in networking and engineering (decreased), and developer/engineer productivity (increased). Other changes are more subtle but still measurable, including worker satisfaction for those in networking or development and positive shifts within the organization’s development philosophy.
And, in fact, there’s one other essential metric: what number of problems your customers notice. When customers and users are unaware of issues because service mesh has things covered, your organization is meeting expectations, constructing trust, and enhancing your fame.
